《恋与深空》首次深度技术分享:如何为玩家创造真实可感世界?
在日前举办的Unite Shanghai 2025大会上,《恋与深空》的引擎技术团队首次对外作了深度技术分享,介绍了该游戏在开发过程中采用的影视级渲染管线与基于物理的渲染技术,这些技术为游戏构建出高度拟真的视觉场景。

在过去一年中,叠纸公司共组织了近40场内部分享,累计参与员工约5000人次。其中,技术类主题的分享占比超过50%。分享者来自公司内多个项目组及技术部门,内容覆盖不同领域的开发实践与前沿探索,形成了常态化的内部交流机制。
以下为《恋与深空》技术分享完整内容回顾:

《恋与深空》渲染底层框架的分享内容主要涵盖【场景渲染优化、光照方案与管线设计、阴影优化】三部分。在开发过程中,我们基于Unity 2019对引擎源码进行深度修改,开发了一套自定义的SRP管线。目前Android线上版本为GLES 3.1,未来也将上线Vulkan版本,持续提升性能,满足玩家对高品质游戏的需求。
1. 场景渲染优化
在场景渲染优化中,我们开发了一套名【RendererGroupRenderer】的场景渲染系统,将每个渲染批次称之为一个RenderGroup。通过这套系统我们实现了以下功能:
自定义静态场景描述:我们去除GameObject,避免了更新大量GameObject时带来的性能损耗。
优化CPU→GPU Upload 频率:主要包括InstanceData和ConstantBuffer的Upload。关于InstanceData的Upload优化,我们在项目初期针对室内小规模场景,采用的是静态生成InstanceDataBuffer,配合BVH分割裁剪的形式。随着项目推进,场景精度要求不断提高,后期便转向在GPU端完成裁剪与instance填充。ConstantBuffer的Upload优化将在后面【单DrawCall性能优化】部分进行详细说明。
CPU侧Burst+Job System并行粗裁剪:对静态物件我们通过Burst+Job System实现了一套高度并发的裁剪系统,同时只在CPU侧进行粗略的裁剪,将细粒度的裁剪任务交由GPU完成。
InstanceData数据形式
业界常用Constant Buffer形式的InstanceData存在一些缺点,比如64KB 尺寸限制、常量缓存小、动态索引时容易发生缓存击穿导致性能下降等。另一种常用形式是用SSBO来传递InstanceData,但这种方法读取性能通常不如缓存未击穿情况下的ConstantBuffer,并且部分安卓设备在GLES下不支持在vertex shader中读取SSBO,这也限制了它的兼容性。同时这两个方案都有共同的问题:依赖动态索引,对低端手机性能不友好。
针对以上问题,我们提出了一种“新瓶装旧酒”的方案——Vertex Stream based Instance Data。
使用PerInstance Step的Vertex Stream作为Instance Buffer;
走Vertex Fetch缓存,无需动态索引,Cache命中率高,无兼容性问题;
通过ComputeShader向Instance VertexBuffer输出,实现GPU Driven。
使用PerInstance Step的Vertex Stream作为Instance Buffer——这是一种在GPU Instancing诞生之初就被支持的Instance方法,既可以避免动态索引带来的性能问题,也避免了SSBO的兼容性问题。我们还可以通过ComputeShader向Instance VertexBuffer输出来实现GLES下兼容性较高的GPU Driven。
最后,由于Unity引擎在底层没有支持PerInstance Step的Vertex Stream,我们对引擎也做了相应的定制,最终暴露给上层的是CommandBuffer中添加的一个DrawMeshInstancedTraditional接口,它需要将另一个mesh作为instance data传进来。我们也加了相应的接口来配置instance mesh中各个数据段对应的顶点semantic。
GPU Driven
我们会依据Group数量与Instance数量,提前分配IndirectParameter Buffer与Instance Data Buffer(这里Instance Data Buffer只是提前分配了空间,实际的数据为GPU Cull时填入)。
同时,我们会预计算每个Group的Instance Offset,并将其存储到Parameter的InstanceStart项,全程只绑定一份Instance Buffer。
此外,我们还需要生成逐物件信息Buffe(包含GroupID、LOD Distance Range、Bounds、Transform等信息),用于在GPU裁剪时获取每个物件的属性。
CPU剪裁:在GPU裁剪之前,我们会先执行一次CPU粗裁剪,以判断Group整体是否可见。从一个根包围盒开始,比较物件包围盒体积总和与合并后包围盒的体积比值,低于阈值就递归分裂包围盒(主要目的为避免两个物件距离过远,拉出一个超大总包围盒的情况发生)。同时结合PVS进一步判断Group的可见性,因为我们没有类似DX12的IndirectExecute,我们的GPU裁剪只能减少instance数,并不能消除Group整体的drawcall,因此需要,通过CPU裁剪尽可能准确地剔除掉完全不可见的Group。
GPU剪裁:GPU裁剪则通过一次dispatch对所有Group进行逐物件3段裁剪,包含视锥裁剪、LOD裁剪、Hiz遮挡剔除,通过裁剪将Parameter的Instance Count加1,并输出InstanceData。
阴影剔除:我们参考了龙之教条分享的方法,将画面深度重投影到阴影空间作为Shadow Reveiver Mask,若Shadow Caster投出的Volume与Mask不相交,就可剔除避免多余阴影渲染。
此外关于我们“为什么没有实现Cluster/Meshlet”部分,首先它在移动端存在较大基础开销,其次在GLES下实现Cluster也存在兼容性问题。综合考虑下,我们认为优先优化单DrawCall的性能更能为我们带来免费且直接的性能提升。
单DrawCall性能优化
在过往的观察中,我们发现许多对于渲染的CPU耗时优化往往过于关注DrawCall数量,而忽视了每个DrawCall本身的耗时。我们认为降低DrawCall数量只是一种优化方法,最终的CPU耗时才是唯一的衡量指标。
现代移动设备与图形标准其实早就可以胜任大量drawcall,这部分在HypeHype引擎团队在Siggraph 2023中也有过分享——他们在iphone 6s上测试了一万个不同Mesh与材质的DrawCall,耗时仅有11.27ms。其他同等的安卓设备也都基本能维持在60帧以上。而在2014年Metal刚刚诞生时,也提出过比GLES多画10倍DrawCall的口号。
11年后的今天,我们仍为DrawCall过多而苦恼的原因,主要来自多方面的开销,包括PSO切换过多、Buffer提交与拷贝、引擎渲染逻辑以及过多RHI接口调用,都会增加CPU负担。因此我们认为性能优化不能只盯着DrawCall数量,而要综合考量这些因素。
PSO切换优化:主要取决于每个项目对shader变体数量和shader复杂度的权衡。RenderGroup渲染队列会根据shader,material,mesh的优先级排序,同时我们对阴影进行特殊处理:无AlphaTest的材质统一用相同shader渲染Shadow Depth,减少阴影渲染时的PSO切换频率。
Buffer提交优化:在GLES下,Map/Unmap buffer会带来显著开销,现代RHI支持的persistent map虽能显著减少upload耗时,但仍无法避免数据从主线程到渲染线程,再到buffer内存的多次拷贝以及memcmp。因此我们采用了以下三种针对性的策略,显著减少了Buffer Upload:
PerRendererBuffer将逐Renderer的参数(如物体所受的环境光SH),存放在由Renderer对象维护的Uniform Buffer中,渲染时直接绑定;
PerShaderBuffer针对不需要逐材质变化的uniform buffer,只在shader切换时提交一次,相比PerRendererBuffer来说,PerShaderBuffer更加灵活,可以支持不同的shader变体;
针对PerMaterialBuffer,我们借用了SRP Batcher代码预生成逐材质buffer并直接绑定。
渲染逻辑优化:商业游戏引擎为保证灵活性与稳定性,渲染时会进行复杂的逻辑判断。比如在Unity引擎内部,每次调用Draw时会先调用一个ApplyMaterial函数,它会在渲染之前更新所有的渲染状态与参数,当DrawCall数量较多时存在可观的耗时。因此我们进行了以下优化:
对ApplyMaterial接口进行了单独拆分,仅在材质或参数需要切换时才由上层主动调用;
只需改变PerMaterialBuffer时,改用简化后的专用接口。
优化后,我们的CPU在在相同DrawCall下耗时减少1/3。
RHI调用优化:RHI调用优化主要的目标是减少除了Draw Primitive以外的其他图形API调用,具体优化包括:
合并相同stride的Vertex&Index Buffer,避免逐Draw Call bind VB/IB,耗时减少15%;
Resource未发生变化时,跳过DeorSet设置,耗时进一步减少30%;SetDeors本身耗时较高时候,而且切换Deor还会增加下一次draw的耗时,这个在Arm的Best Practice Guide里有过介绍。
我们在低端安卓设备上测试了5000个DrawCall的耗时。使用引擎原生的渲染时,渲染线程的耗时是34.79ms。当我们对Buffer提交与渲染逻辑进行优化后,耗时降低到22.97ms。在进一步优化RHI调用次数后,耗时进一步大幅降至了11.8ms。最终我们在DrawCall数量不变的前提下,让CPU耗时减少到了原来的1/3以下。
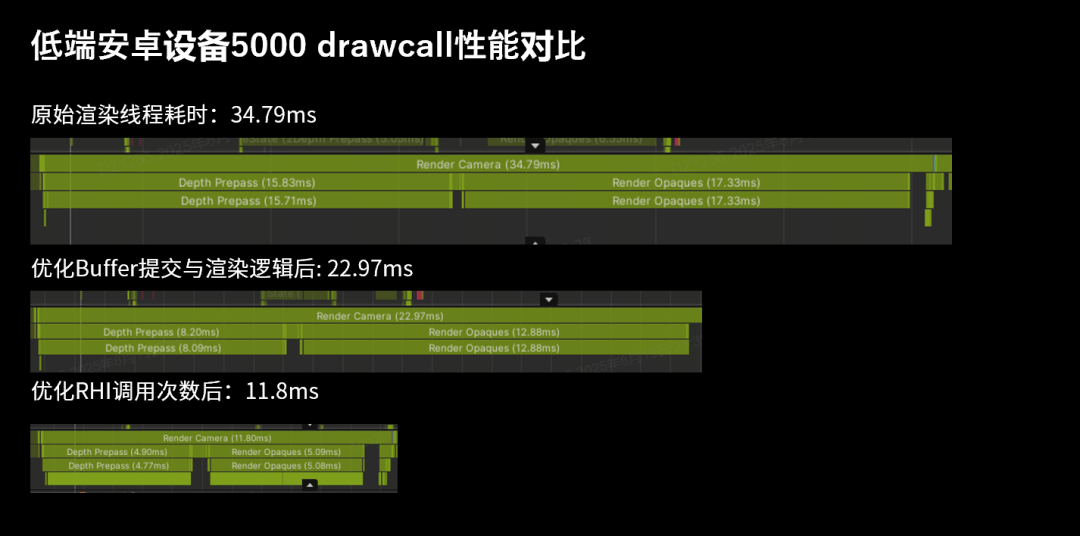
其他优化尝试Benchmark场景测试结果
我们还尝试了一些新的RHI特性,包括:
Multi-Draw Indirect(MDI):在支持的设备上能够带来明显优化,一定程度上改善GPU遮挡剔除可能会提交空DrawCall的问题(CPU端提交减少);
Bindless:然而,Bindless的表现却不尽如人意,即便在最新的安卓设备上也出现了神秘的负优化。结合MDI与Bindless,我们可以实现几乎用一个DrawCall渲染所有物件,但是CPU耗时却比不合批时还更高。这也是一个过度关注DrawCall数量的反面案例。当然,我们期待以后的移动芯片对bindless能有更好的支持。现阶段的话,我们尝试基于Unity Texture Streaming扩展出了一套无Feedback SVT系统作为替代方案,这个方案也还在验证阶段。
从Benchmark场景测试结果来看,RenderGroupRenderer对比原始无instancing渲染,DrawCall减少了1/3,渲染线程耗时大幅减少3/4,主线程耗时也减少了2/3(虽然C,但引擎原生裁剪与GameObject更新耗时减少,整体仍然带来了大幅的优化)。
2. 光照方案
光照方案
前向渲染管线:
我们在项目中选择使用前向渲染管线,包含以下多方面考虑:首先,前向管线在应对美术复杂且多变的需求方面有其优势,我们不需要担心一些材质属性的添加是否会导致GBuffer膨胀。
其次,传统的延迟管线对于移动平台而言带宽不太友好。OnePassDeferred则在灵活性方面存在一些局限,比如无法在RenderPass中间改变RT的尺寸,也不能fetch当前位置以外的像素内容。
在GLES下,FrameBufferFetch的兼容性也存在问题,不同芯片支持的fetch RT数量不同,有的只支持1张RT,需要改成通过PLS实现,但是我们测试PLS的性能并不理想。
另外,引擎自带的逐物件4盏光源对于较大的物件来说不太够用,因此我们尝试了Forward+。但是Forward+在早期设备上耗时太高,若限制逐tile最大光源数,镜头变化时,tile内光源数量不可控,超上限会带来表现bug。
为解决这些问题,我们采用了水平世界空间Tile划分——默认2米一格,分布于相机前方,逐Tile最多4盏光源,128*128 Index Map。这种划分方式使Tile光源重叠状态稳定,便于在制作时及时发现超限问题。
Vulkan版本管线改进
我们在未来的Vulkan版本的管线中增加了基于Subpass的Light Pre-Pass。
在Pre-Z Pass中,我们会输出一张简易的GBuffer RT并且store下来。由于我们的local light光照使用了无fresnel的简化PBR模型,所以我们不需要在GBuffer中输出specular或者Albedo,只将normal,roughness和一些特殊的材质id或属性信息pack到一张RGBA8的Gbuffer上,然后就可以跑一遍类似Deferred Shading的光源Volume渲染流程,将几何光照结果保存到Tile Memory上。
之后在Shading Pass中,我们会把物件再画一遍并fetch这些光照信息,再结合渲染时获得的albedo等材质属性,得到最终的光照结果。
我们将TAA所需的MotionVector Encode为RGBA8,R + G == 0代表无有效速度,这样某些不输出速度的材质可在BA通道存其他信息。
比如我们针对一些简易且大量的植被,会在MotionVector的BA通道上保存他们的UV信息,这样在Shading Pass时,我们只需要后处理获取gbuffer中的几何信息与MotionVector中的UV信息,即可还原出植被的材质表现。
Vulkan版本的管线流程大致如下:首先由PreZ Pass输出Depth,GBuffer与MotionVector,然后计算阴影的遮挡剔除,接着执行阴影的深度渲染,再然后是一些AO和屏幕空间SSS之类的计算然后我们就进入NativeRenderPass,在SubPass中计算ShadowMask,Light Pre-Pass,以及执行正常的Shading Pass。最后退出RenderPass,再执行其他后处理Pass。
Vulkan版本管线改进也存在一定局限,比如Light Pre-Pass只能替换默认Lighting Model,对于需要更多Gbuffer通道的Lighting Model,还是需要采用Forward+。
不过我们提供了一个逐光源可选参数,可以针对某个光源强行使用Standard Lit Model,对所有材质统一处理,这样可以在牺牲Lighting Model准确性的条件下实现让同Tile内的像素受4盏以上灯的影响。
GI
Diffuse GI部分,我们采用了较为传统的Lightmap+Light Probe的方式,Lightmap只保存间接光信息,Light Probe除了正常的逐物件单个采样点的模式以外,我们还提供了一种多采样点模式,能为每个物体设置多个采样点,依据线段、三角形或四面体的重心坐标进行插值。
在以下两张对比图中,左图为单采样点的效果,box的底部为统一的环境光照;右图则为使用两个采样点的结果,可以发现左右两边受到了不同的间接光照。
Specular GI方面,我们主要是基于使用了AABB校正的Reflection Probe。另外对于一些特定的地板或水面,我们还会使用平面反射代理。大致可以看成一种专门用来画反射的HLOD。
此外我们还参考了战神的做法,对Reflection Probe的CubeMap做了归一化。具体来说就是根据CubeMap的像素生成一份环境光照的SH系数,将CubeMap中的像素颜色与该方向的环境光照相除,得到归一化的CubeMap。在实际渲染时,再用每个像素在反射方向上所受的实际环境光照与CubeMap像素相乘,还原出反射颜色。
这种做法的好处是,即使大量物件采样同一个Reflection Probe,不同区域的反射也能产生不同的明暗差别。
3. 阴影优化
功能设计
我们阴影系统的基本设计为:
三级CSM+角色特写阴影/多角色POSM:3级Cascade的CSM+1级角色专属的特写阴影,在某些多角色场景时会使用POSM(Per-Object Shadow Map);
可支持两盏锥灯投影;
ScreenSpaceShadowMask:将以上阴影的结果都将输出到了一张RGBA8的ScreenSpaceShadowMask上;
R:Directional Shadow, G: Local Shadow 1, B: Local Shadow 2, A: AO:R通道保存主光阴影,G和B保存了锥灯阴影,A通道保存了AO信息。
距离剔除
我们首先做了一个简单的距离剔除,根据阴影距离修改ScreenSpaceShadow后处理三角形顶点的深度值,之后再用ZTest Greater渲染,剔除阴影距离外的Shadow计算。
因为在计算阴影时要采样depth,我们需要两份depth分别用于Test与Sample,我们会在NativeRenderPass中拷贝一份Memoryless的Depth Buffer用于Test,尽量避免额外的读写带宽。
半影区域检测
我们增加了半影区域检测功能,先在1/4分辨率下计算一次PCF,随后在全分辨率Shadow Pass里采样1/4 mask,仅对shadow值处于中间区域的像素执行全分辨率PCF,在保证效果的同时降低计算量。
为了避免这样做之后存在某些细节像素检测不准确的问题,我们会分别依据1/4 Buffer中Position的偏导与全分辨率Gather的4个深度值计算两组法线。若法线夹角大于阈值,则判定低分辨率像素不可靠,强行执行全分辨率PCF。
以下为场景的Debug视图,红色区域被我们判定为半影区间,只有这些像素才会执行全分辨率的PCF。
逐像素bias
我们利用Receiver Plane Depth Bias算法实现了逐像素的Shadow Bias。它的原理也比较简单,首先对屏幕空间shadow coordinates偏导应用二维链式法则,求出阴影空间偏导。
利用偏导与PCF采样偏移我们可以求出bias值。对于中心点来说,我们增加了1个像素偏移的bias结果作为起始bias。
下图为固定bias与逐像素bias的对比结果:
左图使用固定bias值,可以看到box的底部有一段漏光区域,并且与光照方向接近垂直的表面存在部分自阴影走样;使用逐像素bias之后(右图),我们只会在偏导较大的区域增加bias,可以在保持细节投影的同时解决自阴影的走样问题。
不过,当屏幕深度不连续时,逐像素bias可能算出错误结果,导致一些漏光现象。为了解决这一问题,需要美术手动指定bias的最大最小范围。
Scrolling Cached Shadow Map
针对DrawCall较多的场景,我们还尝试了Scrolling Cached Shadow Map,具体包括:
缓存CSM深度,对于前后两帧都被阴影视锥完全包含的对象,将上一帧的CSM滚动到当前帧投影位置直接得到阴影深度,避免直接渲染对象;
只对最后一级cascade应用Scrolling,当cascade范围比较小时,大量物体与会与视锥相交,优化效果就会受限;
间隔多帧更新缓存,减缓带宽压力。
在未来,我们还准备支持Local ShadowMap Atlas以及缓存机制。我们将会支持两盏以上的局部灯投影,并且根据光源的屏占比动态调整ShadowDepth精度了,对于远距离的局部光源,也会引入静态缓存支持。

1. 角色光照方案
在角色光照方案中,相信大家多多少少都会遇到以下几类问题:

对这些问题进行拆解,则可以总结为以下3个需求:
基于以上需求,我们进行了具体角色光照方案设计。
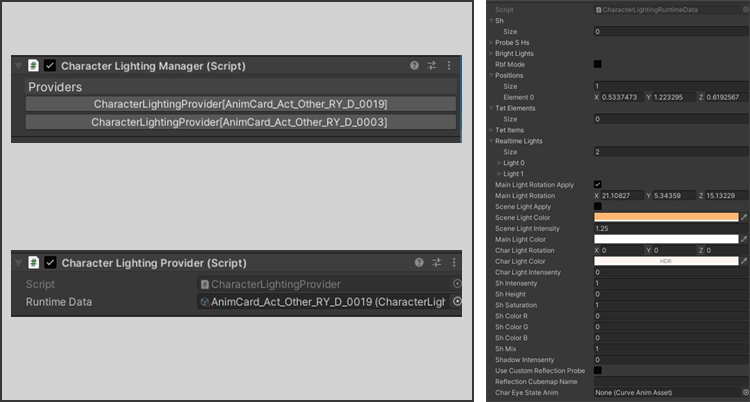
光照是由【直接光】和【间接光】组成的,一般情况下我们只会有一个平行光——我们习惯称之为主光。主光正常照亮场景,但在照亮角色的时候我们保留它的方向,用一个类似后处理盒子的方式覆写主光的颜色和亮度。具体实现方式为:
给Shader多传一份角色主光颜色,角色的Shader在获取主光时获取到的颜色为角色主光颜色;
给角色提供了一盏额外的不投影的平行光用来做轮廓光;
同时预留了两个额外光给角色,额外光可以是任意的点光和射灯组合,可以正常照亮范围内的角色和场景物件( 因为一个2米的格子最多四盏额外光,所以将2个灯光划分给角色)。
间接光我们使用Unity的LightProbe系统来创建探针,自己实现了保存间接光到探针里的部分,把场景的探针和角色的探针分开两套,分别存储和使用;
环境光高光我们使用同一个反射探针,但对于一些特殊的材质,我们提供了材质上输入CubeMap覆盖环境的反射探针的选项。
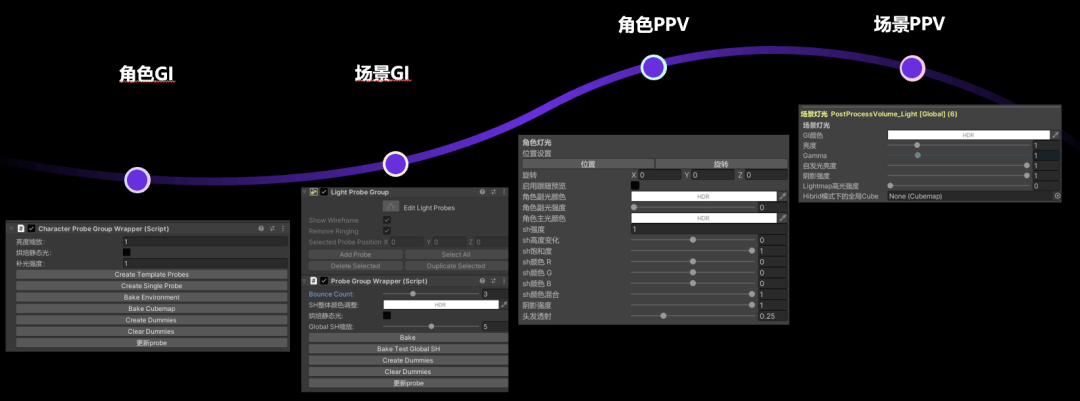
我们把这些影响角色的光照信息存到一个ableobject里,由灯光师调整好之后保存为一个模板;下方右图为角色灯光方案保存的信息,包含了上面提到的两盏平行光,两个额外光,还有探针保存下来的sh,以及一些后处理盒子上可以额外调整的信息和是否使用自定义的反射探针。
最后用一个manager使用类似栈的方式去管理,这里选用栈的管理方式跟具体使用强相关——通常情况下除了加载新的灯光方案之外,最常用的一个功能就是还原上一个灯光方案效果,因此我们采用了栈的管理方式。
到这里,这个方案已经具备 了角色/场景分开、可实时切换、支持定制保持模板这些功能。最后我们把切换灯光方案定义成剧情编辑器上的一个事件行为,支持了 可衔接光照动画。
可衔接光效果如下所示:
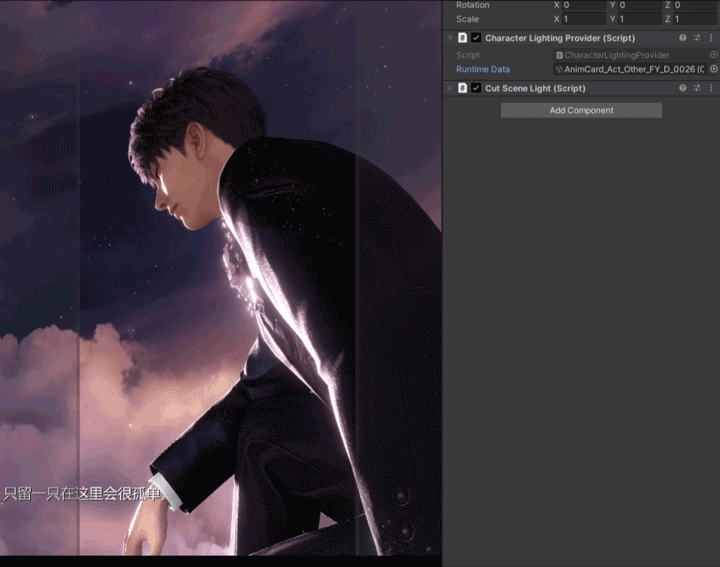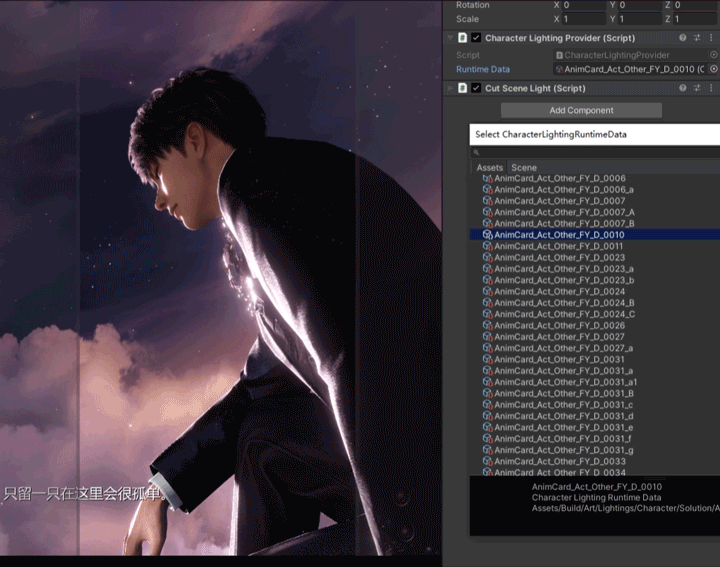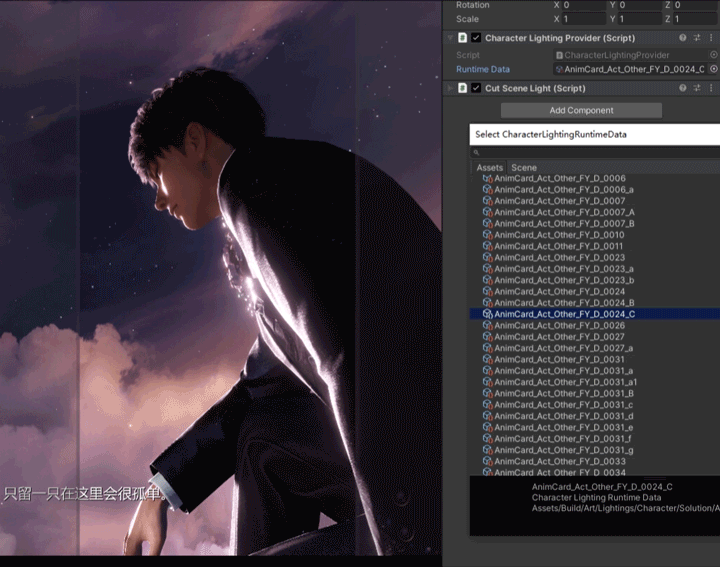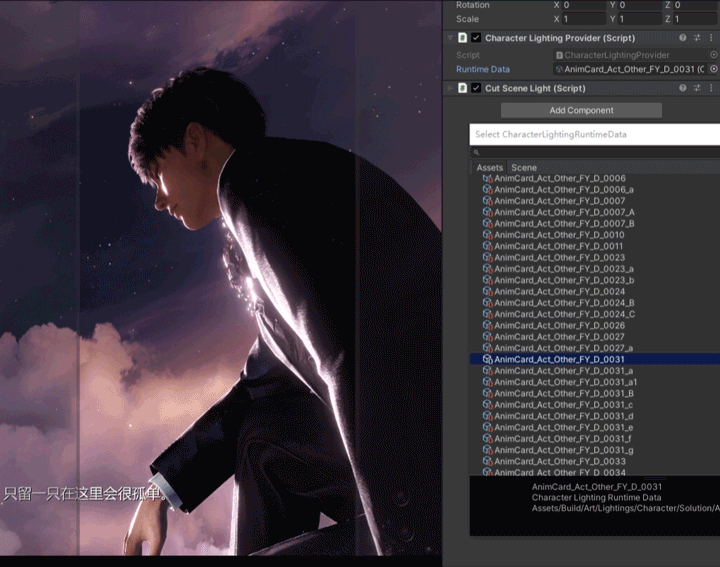
下图为项目专用剧情编辑工具,基本上所有的灯光和阴影相关的参数及部分后处理、物理效果都可以在这个剧情编辑器控制。
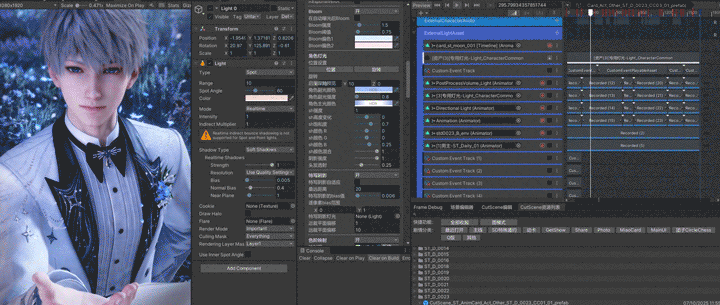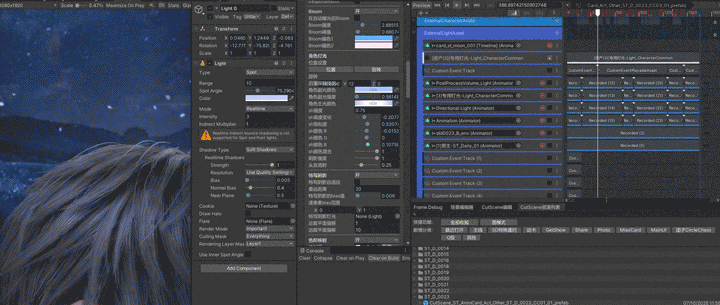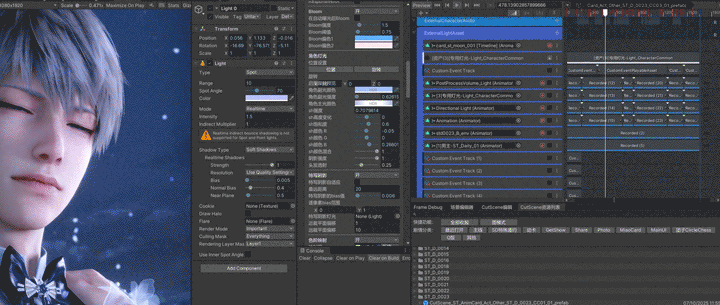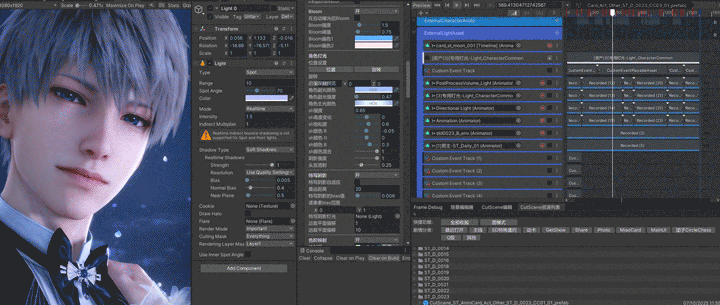
2. 特写阴影
光和影一直都是密不可分的。如前文所提到,我们的阴影方案为三级CSM加特写阴影,实现原理就使用角色身上的一根可指定的骨骼做球心,构成一个指定半径的球,用这个球来构建和生成这张阴影图,在屏幕空间阴影的时候会进行精度比较,使用这张阴影图和级联阴影中精度较高的一张作为这个像素的Shadow Map。
通过以下动图可以看到,角色原本整个都在主光阴影里,打开特写阴影的时候变成了可以被主光正常照亮,就是因为特写阴影修改了近裁切平面;也就是说我们的特写阴影是一张单独可调参数的阴影图,具体参数包括远近裁切平面,最远距离,还有使用哪一盏光和往往最让人头疼的bias。

3. 皮肤细节
皮肤上我们聚焦一些细节表现,具体以脸红效果和流汗效果为例。
脸红效果
通常来讲,脸红的过程是一个逐渐变化并且不同区域变红程度不一样的过程,比如大部分人在脸红的时候会先从耳朵开始红,然后是脸颊,偶尔会有整张脸变红的表现。
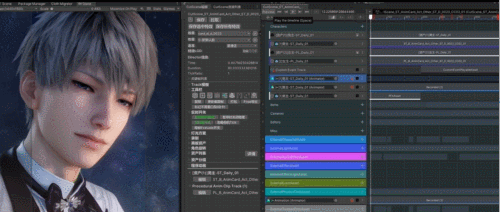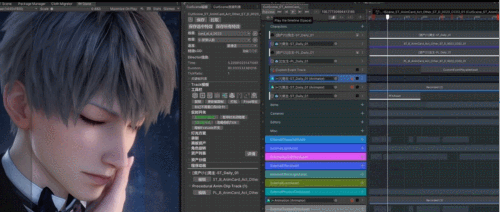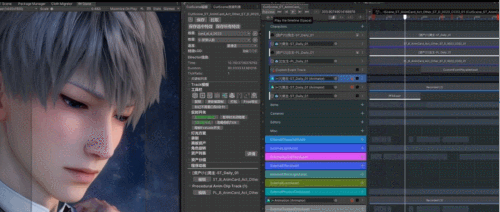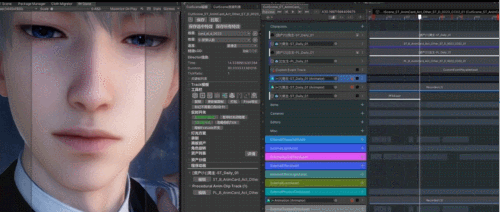
为了模拟这个过程,我们采取了以下方式,使画面更加生动和真实:
手绘遮罩:基于遮罩纹理控制脸红区域、颜色梯度与强度;
多通道独立:可分别调节面部、耳朵、鼻子等不同区域的红晕效果;
预存变化过程:脸红的过渡过程分通道记录在对应曲线上,实现自然的情绪表达。
流汗效果
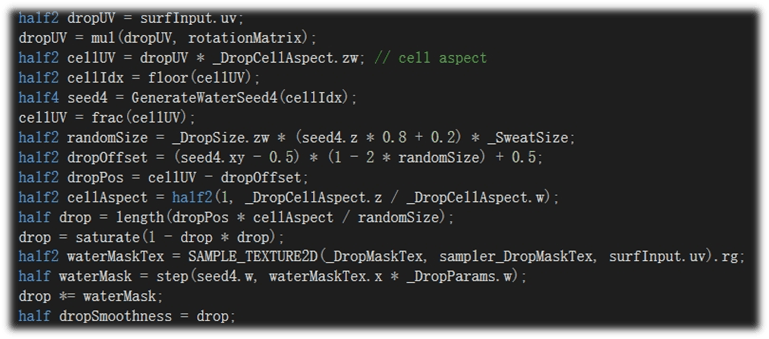
我们游戏里提供了运动陪伴功能,男主会进行一些运动训练的陪伴,因此也就需要提供相应的流汗效果。具体实现主要通过以下三个方面:
材质与粒子结合:材质着色器模拟皮肤表面光泽与湿润度,汗珠效果提供附着在皮肤上的材质实现和vfx实现可供选择;
遮罩控制流汗区域:使用遮罩图确定材质流汗区域,增强流汗效果的真实性和艺术性;
数据自动化传递:主控参数变化自动驱动材质与粒子参数。
下图为一些具体的计算方式与最终效果示意。
△计算汗滴生成位置并修改汗滴位置粗糙度
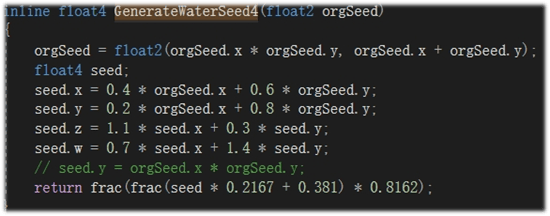
△通过uv格子id生成随机数

△模拟汗滴下落的轨迹

△运动陪伴系统流汗效果

物理效果的分享主要围绕四个方面,包括布料模拟实现、实时表演控制、基于Unity DOTS的开发、碰撞检测模块。
1. 布料模拟实现
为了解决项目中的一些针对性的问题,我们内部自研了一套布料模拟的系统。
基于骨骼的布料模拟系统:StrayCloth
StrayCloth采用XPBD结合sub step的模拟方式。相比PBD,XPBD的优点是摆脱了迭代次数和时间步长的依赖,结合Substep可以显著提升解算的收敛效果。
比较特殊的地方在于,我们使用骨骼作为模拟粒子,也就说每个粒子除了位置以外还带旋转信息。
在具体的substep实现中,我们针对不同性能压力场景采用动态的子步幅时间,在1/200 -1/300之间。并且对场景中的运动对象进行运行插值,这样碰撞的效果会更加稳定。事实上运动插值虽然性能开销不是很高,但是由于类型众多,比如有静态粒子,碰撞体,风场等,实践起来还是非常麻烦的。

为什么使用骨骼而不是代理网格?主要出于以下三个原因:
恋与深空在剧情、战斗、换装中的表现需求复杂,骨骼方案可以很好的过渡动画和解算;
在可控性需求和移动端性能限制下,骨骼方案给美术的自由调节空间更大;
使用骨骼+约束可以构建类似Mesh的结构来达到相近的效果。
骨骼约束方案
在已有的骨骼布料方案里,骨骼约束实现常采用基于Local和Global形状约束的实现方式,虽然简单快速,但是也有明显的缺点——在用来做布料模拟时,效果偏向卡通风格,不符合《恋与深空》追求的3D写实风格;而且它的参数调整不直观,因为它有gloabl和local两个弯曲强度参数,不利于美术调整以及在不同场景下的效果匹配。
因此,我们在骨骼约束方案上,选择了基于Cosserat Rod的骨骼约束。它的优点包括:
效果上更加自然,贴近恋与深空整体的写实美术表现风格
参数调整上更加直观, 并且三个轴向强度分离,在一些场合比如模拟裙子的时候,可以通过各向异性的弯曲强度来近似裙撑的效果。
头发模拟中可以直接复用, 所以我们头发和衣服也可以共用一套约束。
具体效果可以参考最新日卡的表现:

布料与角色连接
布料和角色的连接主要通过两种方式:
层级:静态骨骼直接受角色的骨骼动画影响,根据层级关系进行移动。
这种方式比较简单,在一些偏向于刚性的连接部位时表现良好。但是对于一些骨骼交界有多个骨骼影响或者存在一定幅度拉伸和收缩的较为复杂的位置,例如手肘、肩部、腰部,表现上容易出现布料和角色分离。
吸附:静态粒子受角色模型的锚定三角形控制。并行bake mesh,通过重心坐标每帧计算更新。
对于三角形存在的退化的特殊情况,我们使用三角形顶点的蒙皮骨骼的变换,进行加权平权来更新静态粒子的transform。

碰撞方案
碰撞方案上,我们使用一个dynamic Bvh来作为场景碰撞的broad phase管理,每个角色作为sub tree包含其内部的碰撞体作为sub tree node。
同时,我们通过角色id,分享可见性还有部件类型,这个三个规则来实现不同角色、不同部件的碰撞规则的共享规则管理。
在narrow phase 当中,我们不直接生成contact,而是缓存碰撞体对,在substep中再具体的解决,因为我们采用的sub step的优点,大多数情况下直接使用DCD就可以避免一些快速运动下造成的穿透问题,不需要引入ccd或者predictive contact等一些操作。
Mesh Collider实现
对于参数化的几何碰撞体,例如plane、capsule、box,可以比较简单的解决它们和粒子以及edge的碰撞。在肩颈和胸背部等复杂部位,参数化的几何体难以准确的表达角色模型形态,表现上容易发生穿透,所以在这些部位我们大量的使用Mesh collider。
但是mesh collider作为不规则的凹体,有时也可能是非闭合的,想达到精准的碰撞效果相对参数化几何体就比较困难,特别是在移动设备下,因此我们采用散列哈希来作为三角形的粗略查找方式,结合缓存的邻近三角形结果,在迭代开始前生成一次粒子-三角形碰撞对,后续的迭代中判读粒子是否在三角形的范围,如果超出三角形的范围,通过模型的三角形邻接关系进行限制步幅的三角形查找,来获取最近的三角形,并且缓存结果作为下一次使用。
下方的动图是项目中的一些具体表现示例,可以看到表现上是比较稳定的。

Face Collider
面部碰撞体可以看作是特殊的Mesh collider,相对于基本的mesh collider,它形态较为固定,也较为平滑,从模型中心出发基本上没有三角形重叠,所以我们使用16x16的CubeMap来预计算各个方向上的三角形,这样碰撞计算时可以快速查找到邻近的三角形。

层间碰撞
游戏当中布料模拟的自碰撞是最难处理的部分,出于性能上的考虑,我们给出的方案如下:
使用spatial hashing作为查找加速结构
由美术预先分层,只考虑层之间粒子和三角形碰撞
避免层之间卡住的情况,只计算粒子和三角形单法线方向的碰撞
由美术预先对布料进行分层,只考虑这些层之间的碰撞。使用散列哈希作为查找的加速结构,并且为了避免层之间卡住的情况,我们只考虑单法线方向的碰撞,如果已经穿透了则略过,交给后面的步骤来修复。
实际实践中,我们使用上一次substep的粒子位置来和当前的粒子位置进行碰撞,这样可以很简单的就解耦数据避免依赖。

层间穿透分离
对于层碰撞已经穿透的部分,我们参考了untanging cloth的方式,使用了一个轻量的解决办法,通过布料分层,从布料的固定点出发,计算不同层级的边和三角形的交点,因为我们的资产结构必定为一个uniform的网格,因此可以通过网格交点比较简单的推测出其它粒子的推出三角形,最后对穿透的粒子-三角形对施加弹簧约束来解决穿透。在实践中由于substep的关系,穿透的概率相对不大,因此我们采用分帧分块执行来减轻性能压力。
2. 实时表演控制
恋与深空剧情表现中大部分的物理表现,都是依托于cutscene来实现的各种物理效果的控制和调节。我们的工具同学开发和维护了一套非常强大的cutscene工具,在他们的基础上我们开发了多种的功能轨道来具体调控物理效果。
这边是我们一个动卡的Cutscene Physcs Track的例子,因为我们美术同学对于画面表现扣的非常细,所以可以看到整个物理轨道的配置还是非常复杂的。
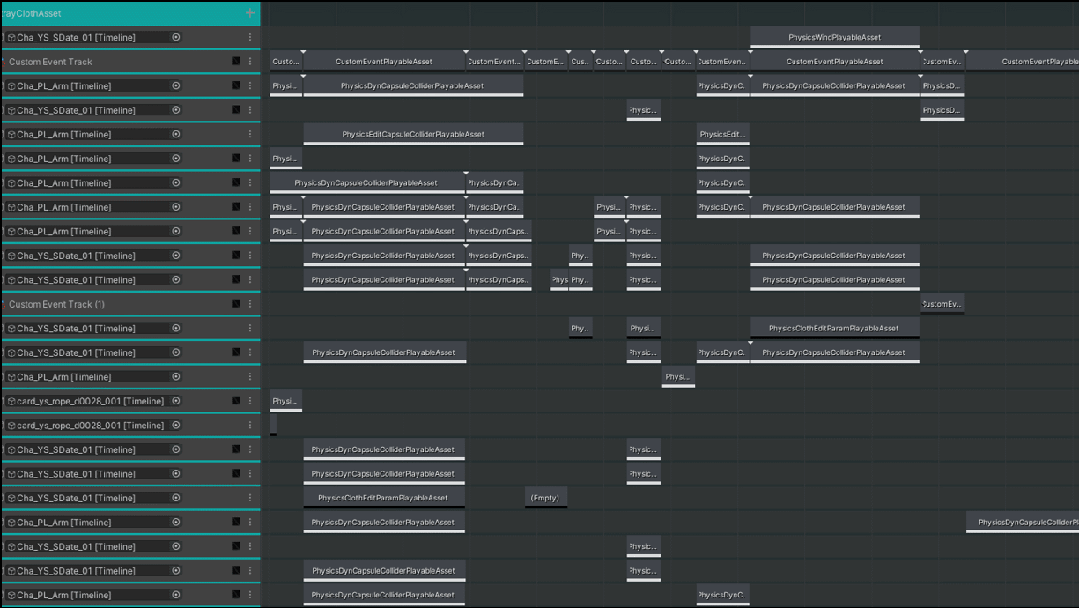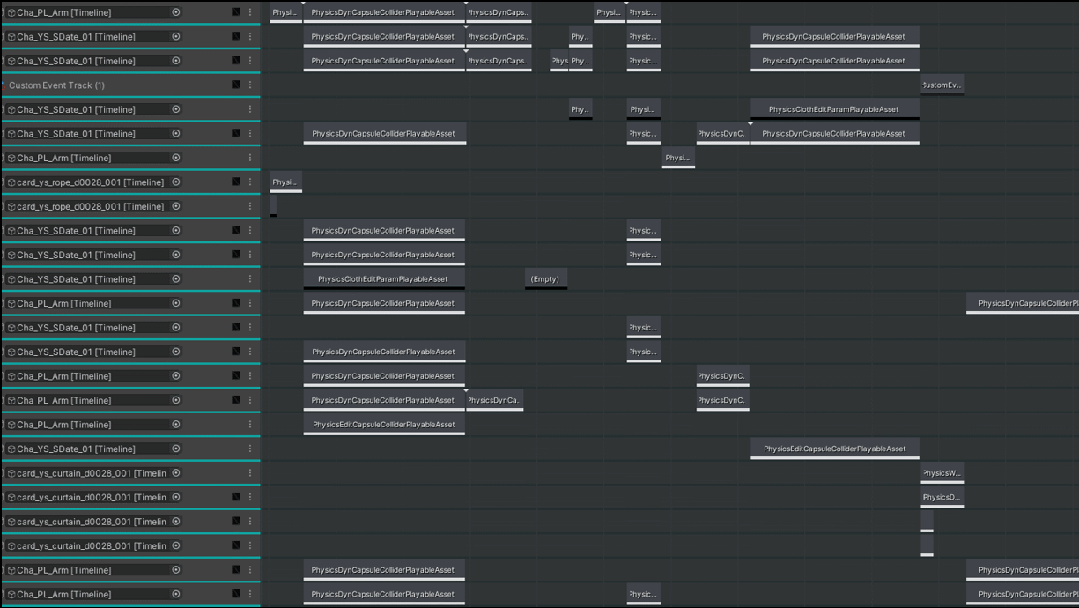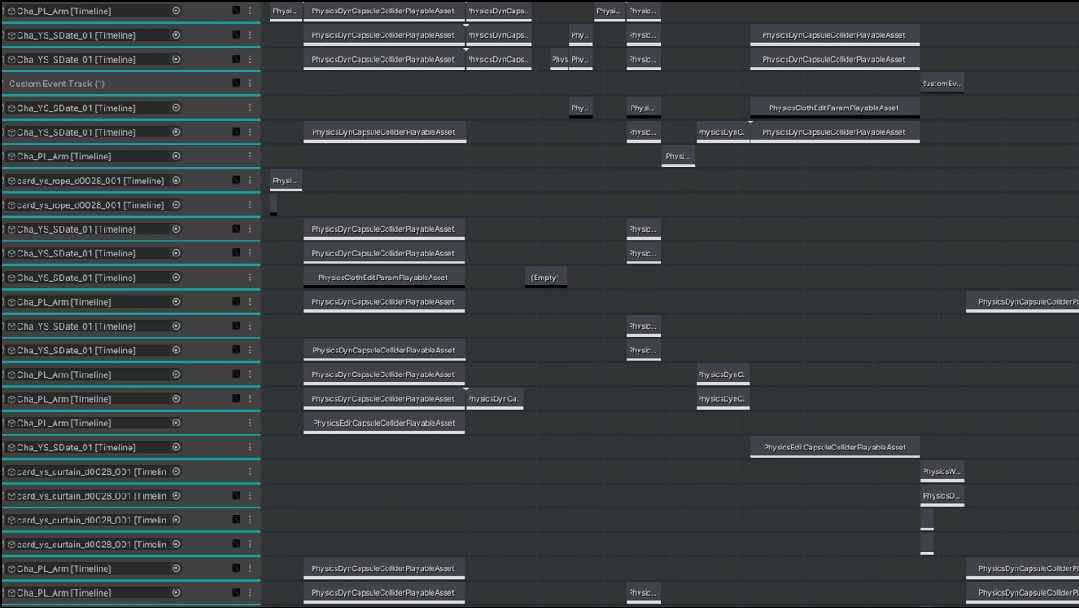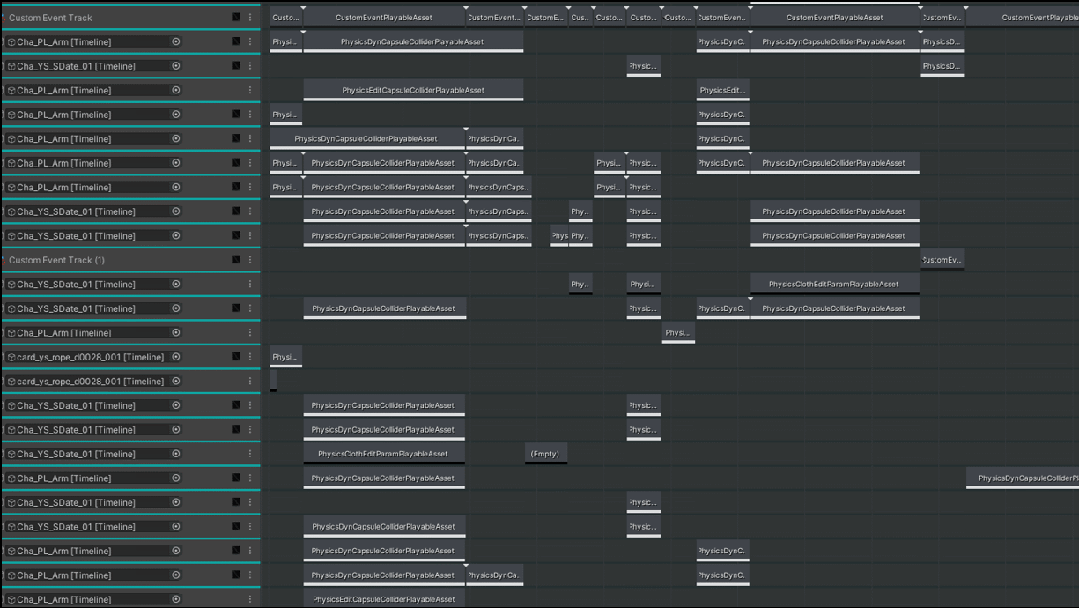
△Cutscene Physcs Track 示例
SmoothBlendPose Track
在表现当中,一个非常常见的问题就是动作瞬切切换带来的物理抖动,无论是在剧情表演中还是换装中,都经常出现。
我们开发了一个较为通用的办法,通过记录初始物理姿态,在切换的时候在初始姿态和当前姿态进行姿态插值计算,这样就可以大幅度的缓解抖动,当然这个会带来一些时间开销,一般会在几十毫秒左右,在大多数情况下都可以接受,提供一些参数例如插值次数,插值的步幅大小来让美术可以根据实际需要来去调整。
Pose Track
当然,SmoothBlendPose存在局限性,不能保证的完全顺畅,特别是在一些剧情表演的复杂镜头切镜下。我们还提供了一个比较直接的方案——离线直接保存某个时间帧的物理状态,在播放时,将保存的物理状态直接应用到布料上,这样就可以完美避免切镜带来的问题。

Edit Param Track
单一的物理资产是很难满足剧情当中的各种不同场景下的表现的,比如有的时候希望布料软一些硬一些,阻尼大一些小一些。我们提供编辑参数的轨道,通过这个轨道来实时的编辑修改参数,绝大部分的参数都可以覆盖大,可以非常方便的针对一小段时间帧进行修改。这个参数修改还可以用来做一些特殊的效果,比如动图当中的利用编辑约束参数来实现的断裂的效果。

Animation Track
完全的物理效果实际上不足以支持起整个画面方方面面的表现的,很多时候表现上需要动画和物理的结合来做一些互动。我们通过动画轨道来实现动画和物理的衔接和融合,精细的控制不同时间帧范围下的表现。在实际制作流程当中,动作在dcc里和最终进引擎的表现差异是比较大的,包括一些引擎的实时rig系统修改后,动画可能和其它地方有穿透,所以我们在动画融合的基础上,可以叠加上物理的碰撞效果,来避免一些穿插。
动图当中展示是项链在物理和动画的交互效果,包括从物理到动画的状态切换以及在不同动画之间的切换。

Collider Track & Wind Track
Collider Track与Wind Track可以在cutscene中动态的创建、销毁碰撞体和风场。根据不同画面需求,灵活改变碰撞体和风场的状态。通过角色、部件类型、还有布料的层分组来细节控制所要影响的对象范围。
并且,碰撞体和风场轨道的绝大部分参数可以添加动画帧控制,包括碰撞体的形态大小、风场的方向、范围、强度、湍流等,方便美术把控物理效果,精准控制变化。
动图当中是轨道胶囊体和风场的一些表现例子。

3. 基于Unity DOTS的开发
Jobs + Burst + Mathematics
DOTS这套工具非常强大,在C。我们的物理系统使用DOTS完全构建在C,功能迭代和debug都非常便利。目前来说我们最高可以支持2000+骨骼粒子的模拟。
当然,我们也针对性的在项目中,做了一些优化进一步提升性能。

Cache Job
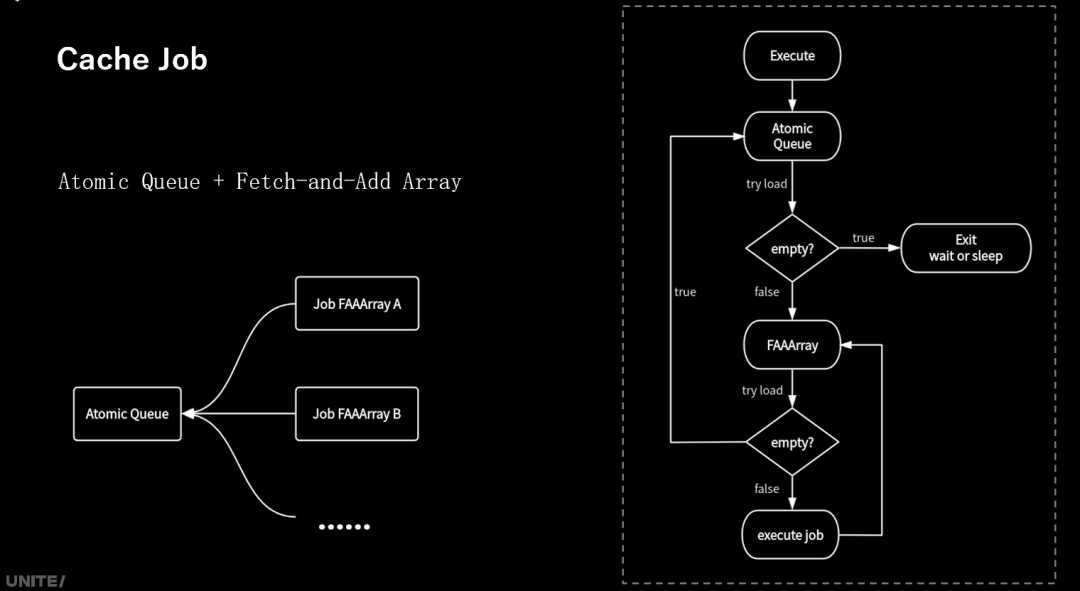
模拟中的job数量和依赖关系确定,job data并不频繁变化,帧内一般为相同数量和依赖关系的job组多次循环执行,Unity Jobs 在发起任务时每次都需要重新创建job,虽然可以提前发起任务缓解,但是依然会卡主线程。并且在执行完成job还需要clear。基于以上的观察,我们开发了Cache Job的方案,预先创建好job data,然后每次执行时复用,避免每次重新创建job带来的性能开销。
实现上比较简单,因为是一个专用的结构,只考虑一些固定的使用场景。额外添加了一个Atomic Queue用来存cache job,使用fetch and add array 来存具体的job。右边是worker执行cache job的流程示意图。
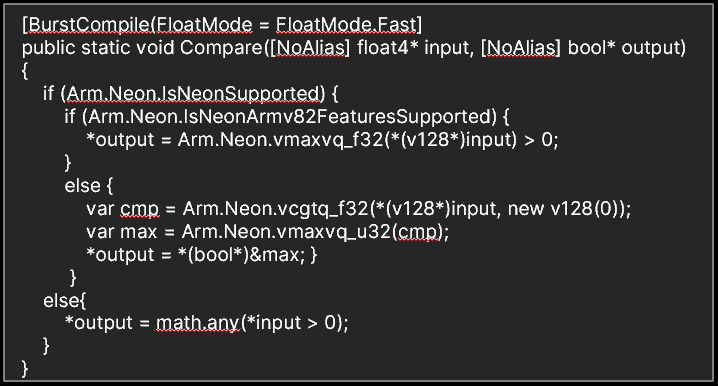
Neon Intrinsics
Burst会针对不同平台生成高性能的simd code,在Burst Inspector中可以非常方便的查看。经过检查Burst Inspector和实机测试,在某些场合下也可以通过手写Arm Neon Intrinsics来进一步提升性能。
这里给出例子是判断向量是否存在大于0的元素的实现。
Dot(float4)
对于点乘,我这里列出了3种方式,使用neon intrinsics相比于mathematics在测试用例中可以获得约30%的性能提升。如果目标机型支持armv8.2的话,可以使用新增的规约加法指令,来进一步的提升性能。一般来说现在市面上的大部分流行机型都是支持armv8.2的。

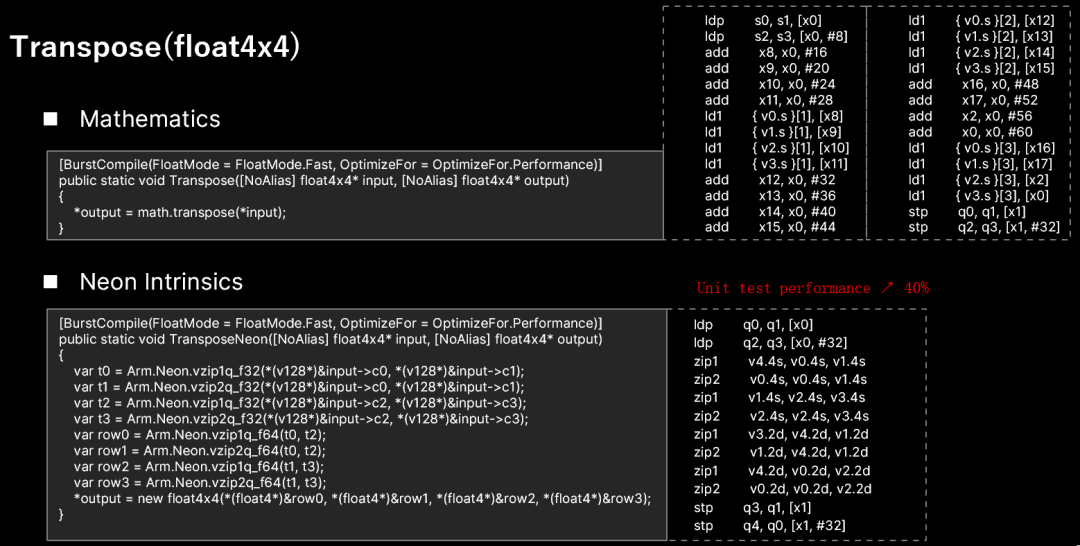
Transpose(float4x4)
对于转置计算,可以看到mathematics生成的assembly code看起来性能是非常低的,通过手写neon intrinsics, 可以得到一个巨大的性能提升。
如果只是纯粹的需要转置,可以直接使用交错读,这里这样实现因为在我一般的实际使用中是通过对4个float4转置来将点乘变成矢量乘。
这里只是给出这两个项目里比较常用的例子。因为mathematics的代码一般被内联,在具体优化时还需要根据代码的上下文进行具体的优化,可以结合burst inspector和真机测试来进行具体的性能测试。
4. 碰撞检测模块
为什么要脱离Unity成熟的物理模块重新开发?
Unity 本身具有基于physx的一套成熟的物理模块,而脱离Unity成熟的物理模块重新开发,主要基于以下考虑:
恋与深空有相当多的不同种类的玩法,玩法间的layer设置相对独立,非常希望能够各自维护一套layer设置。
有些模块例如战斗需要特殊的Trigger触发和退出机制希望在底层就可以支持,对于执行流程也希望有更灵活的控制。
最后是在性能探索上我们也有一些想法,就是在仅需要碰撞检测的情况下,利用DOTS能否提升性能?

《恋与深空》中的实现包括:
基本实现了所有原生的碰撞查询功能
定制化的Update和Trigger逻辑
线程安全的查询接口,上层可以无负担调用
结合DOTS的轻量化结构实现,在性能测试中,最高可获得~15%的提升
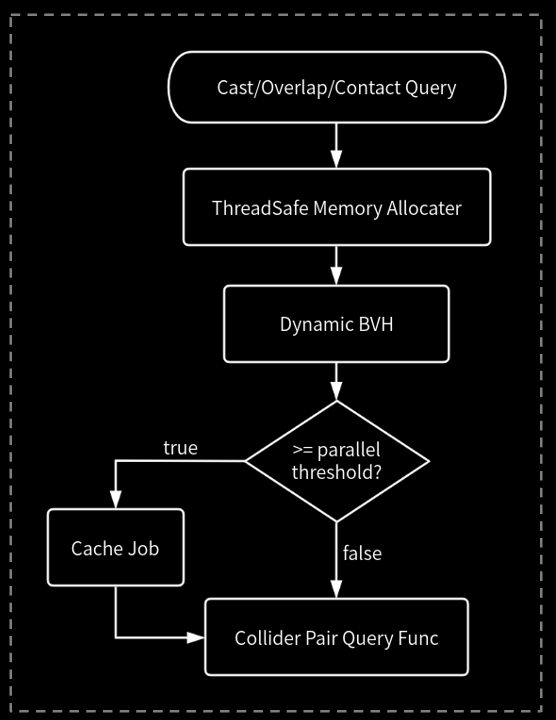
查询流程示例
由于真机上,我们实际的线程数量是固定的为4,所以对于memory allocator可以预先按照线程数量分配好,在分配时可以直接根据当前线程索引来获取。
使用基于SAH的dynamic bvh作为broadphase加速结构,在插入、删除以及超出范围的移动时,对当前操作节点的邻近的几个层级节点进行旋转平衡。
因为碰撞检测的功能目标相对概括,对于精度要求没有那么高,所以我们也适当的牺牲一些精度简化了一些碰撞检测算法来提升性能。
触发流程示例
为了满足战斗模块的需求,我们设计了特殊的trigger触发逻辑,Trigger的 Enter 和 Exit必须要成对出现,可以看到以下流程示意图中,在a触发b的函数中移除b后,会触发所有和b存在overlap的collider,这里和unity原生的有所不同——原生的unity中在trigger逻辑中删除掉b是不会触发其它碰撞体的trigger的。最后,我们通过History计数来标记collider的版本,解决复用逻辑可能会导致的一些潜在问题。

招游戏产业编辑