【CICC原创】面向网络空间认知战的大语言模型:技术与挑战
(《指挥与控制学报》刊文精选)
引用格式:杨光飞,孙畅,刘振东,缪永飞. 面向网络空间认知战的大语言模型: 技术与挑战[J]. 指挥与控制学报, 2024, 10(6): 643-652.
YANG Guangfei,SUN Chang,LIU Zhendong,MIAO Yongfei. Large Language Models for Cognitive Warfare in Cyberspace: Technologies and Challenges. Journal of Command and Control, 2024, 10(6): 643-652.
摘要
《孙子兵法》云:“不战而屈人之兵”,从作战效率和作战效果而言,这是一种费效比极佳、“善之善者”的作战方案。在现代战争中,网络空间认知域作战构成了一个多维度战略框架,它通过融合物理领域的行动、信息领域的利用和认知领域的防御与攻击,旨在在网络空间夺取敌人的意志、信念、心理和思维主导权。网络空间认知域作战方式融合了传统的舆论战、心理战、法律战,以及政治战、经济战、文化战等多种战术手段,形成了一个综合性的作战体系,具有“全天候、不宣而战”的特点,极大程度上助力实现“不战而胜”的战略目标,对我军新型战斗力的塑造起到了关键作用。
LLMs基于机器学习技术,借助其强大的生成能力和理解能力,能够被用来为认知层面的攻击提供支持[2],也使得生成面向特定语境的高复杂度的信息成为可能。这些信息能够更深刻地触动目标群体,同时使得影响活动更不易被察觉和消除。不仅为更多不同类型的行为者发起虚假信息宣传活动打开了大门,也为覆盖大量受众的高度可扩展的宣传活动创造了潜力。
1
LLMs驱动的网络空间认知战
1.1 LLMs发展历程
学术界一直以来都在致力于研究让机器达到与人类相同水平的沟通、理解和创作能力。随着以ChatGPT为代表的预训练语言模型的出现,这一愿景才开始逐步走向现实。LLMs的发展过程可以大致划分为4个阶段:
1)词嵌入和序列模型。词嵌入和序列模型是自然语言处理(Natural Language Processing, NLP)领域的关键技术[3]。词嵌入将词汇映射为固定维度的向量表示,有效地捕捉了词汇的语义信息。2013年,Mikolov等研究者推出了Word2Vec[4]。Word2vec是词嵌入的典型算法,它通过上下文信息学习词汇的向量表示。序列模型在处理自然语言序列数据方面具有显著优势。RNN(Recurrent Neural Network,RNN)是经典的序列模型,但存在梯度消失和梯度爆炸的问题[5]。为解决这一问题,LSTM(Long Short-Term Memory,LSTM)和GRU(Gated Recurrent Unit,GRU)[6]算法相继被提出。LSTM通过引入门结构和细胞状态,实现了长期依赖信息的有效传递。GRU是LSTM的简化版本,它将遗忘门和输入门合并为更新门,参数更少,训练速度更快。词嵌入和序列模型的发展极大地推动了自然语言处理技术的进步,为机器翻译、情感分析等任务提供了有力支持。
2)自注意力机制模型。2017年,自然语言处理领域迎来了一个关键性的转折点, Vaswani等开创性地提出了基于自注意力机制的Transformer模型[7]。Transformer模型通过自动捕捉序列内部的关联信息,实现了对长距离依赖关系的建模。自注意力机制的核心思想是,对于序列中的每个词,模型会根据其与其他词的关联程度分配不同的权重,进而更好地捕捉语义信息。Transformer模型是自注意力机制模型的一个典型代表,它由编码器和解码器组成,编码器通过自注意力机制捕捉输入序列的内部关联信息,解码器则通过自注意力机制和编码器-解码器注意力机制生成输出序列。Transformer模型的出现极大地推动了自然语言处理领域的发展,为文本生成、机器翻译等任务提供了新的解决方案。
4)大语言模型。自2018年以来,以GPT系列为首的大型Decoder-Only架构模型预示了人工智能领域一个全新时代的来临[9]。GPT3(generative pre-trained transformer 3)是一种典型的大语言模型,由OpenAI团队于2020年推出。GPT3模型拥有1 750亿个参数,是迄今为止最大的人工智能语言模型之一。GPT3模型采用了Transformer架构,能够有效地捕捉文本中的长距离依赖关系。GPT3模型不仅在自然语言生成任务中取得了令人瞩目的成绩[10],还可以应用于文本生成、文本分类、机器翻译、问答等自然语言处理任务。GPT3模型的出现标志着大模型在自然语言处理领域的重要地位和发展潜力。在GPT3之后,OpenAI团队继续推出了其他版本的大模型,如GPT3.5和GPT4。这些模型在参数规模、模型结构和训练方法等方面进行了进一步的改进和优化,以提升模型的性能和应用效果。例如,GPT3.5在GPT3的基础上引入了基于人类反馈的强化学习(reinforcement learning from human feedback,RLHF)方法进行微调, 显著增强了模型在生成连贯且准确的文本方面的能力。。GPT4 则进一步扩大了模型规模,引入了更多的训练数据和改进的训练技术,以实现更高质量的文本生成和应用效果[11]。大模型的发展对于自然语言处理领域的研究和应用具有重要意义,可以帮助人们更好地理解和处理自然语言。未来,随着计算资源和算法技术的不断发展,将会有更加先进和高效的大模型的出现,进一步提升自然语言处理的能力和应用范围。
1.2 LLMs的优势
LLMs的发展为认知战领域带来了根本性的技术变革,LLMs在泛化性、多模态等多个关键维度上大幅超越了传统的数据处理和分析手段[12]。这些优势包括强大的零样本学习能力、高度泛化与自适应能力以及强大的多模态数据处理能力[13]。
1)强大的零样本学习能力。LLMs的一个显著特点是,它们能够利用半监督甚至无监督学习的策略进行训练,大幅减轻对高精准度标注数据的需求[14]。在网络空间认知作战领域,网络空间环境通常是不确定和动态变化的,难以获取有标签的高质量训练数据,LLMs可以通过其强大的零样本学习能力对缺乏高精准度标记的数据进行学习,极大地降低数据收集的难度和成本。LLMs能够更高效地整合并解读来自不同数据源的文本、图像和视频等多模态信息,且能在动态变化频繁的网络空间中迅速且精确地做出决策。
2)高度泛化与自适应能力。LLMs相较于传统的机器学习方法展现出更高的泛化和自适应性[15],这在认知战领域尤为重要。网络空间认知战的动态性和不断发展要求解决方案能够迅速适应新的挑战和未知情况。而传统的机器学习方法往往针对特定领域的特定任务设计,缺乏足够的灵活性和可扩展性。在这种背景下,LLMs的高度泛化和自适应能力成为其显著的优势。
3)强大的多模态数据处理能力。在网络空间认知作战领域中,每个时段都会有海量的各模态的情报数据产生,如文本数据、图片数据、视频数据等。LLMs具备极强的多模态数据处理和并行处理能力,能够快速对这些数据进行分析筛选,提取出有价值的信息,为网络空间认知作战系统提供更准确和全方面的多模态数据分析支持。
1.3 LLMs的实际应用
大模型的研究和应用主要基于Transformer模型,并通过增加训练数据量、引入自动化生成指令和偏好数据等方法来提升模型的性能和应用范围,国内外主要大模型及其主要技术方案如表 1所示。
表 1 主要大模型及主要技术方案
Table 1 Main LLMs and main technical programmes

尽管学术界已经推出了一系列大模型,例如复旦大学的Moss大模型、中国科学院自动化研究所的紫东太初大模型开放平台、上海人工智能实验室的InterLM等,但在清华大学基础模型研究中心和中关村实验室共同发布的《SuperBench大模型综合能力评测报告(2024年3月)》[16]、SuperCLUE团队发布的《中文大模型基准测评2024年4月报告》[17]、以及由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立的LMSYS Chatbot Arena Leaderboard等大模型能力评测排行榜上,产业界的大模型综合能力普遍位居前列。这一现象主要得益于产业界在高资本密度和高人才密度方面的优势,其资金和人力资源的投入远超学术界。尽管学术界在这些方面相对受限,但仍然可以从产业界的大模型技术路线研究中汲取经验,用以提升自身自研模型的能力。同时,如何将大模型应用于特定行业,以实现其实际功能,例如在网络空间战中的应用,也是学术界可以进行研究的方向。学术界可以通过深入研究大模型的技术细节,并关注其在实际应用中的效果和效能,以推动大模型技术在各个领域的广泛应用和深入发展。
1.4基于LLMs的认知战智能决策
为了实现对复杂社会系统的有效管控,认知对抗的本质在于将各种不确定性转化为确定性,将多样性统一化,并实现灵活和高效的管理[18]。利用PREA 环可以建立基于LLMs的军事体系指挥控制活动的一般规律,从筹划-准备-执行-评估 (planning-readiness-execution-assessment, PREA)环开展 “5W+H” 设计和各种计算推演。基于LLMs的认知战PREA环如图 1所示,其针对最终目标利用LLMs生成相关预案,事件发展过程中不断评估物理态势及舆论态势,进而调整行动方案,以达到最终目标。
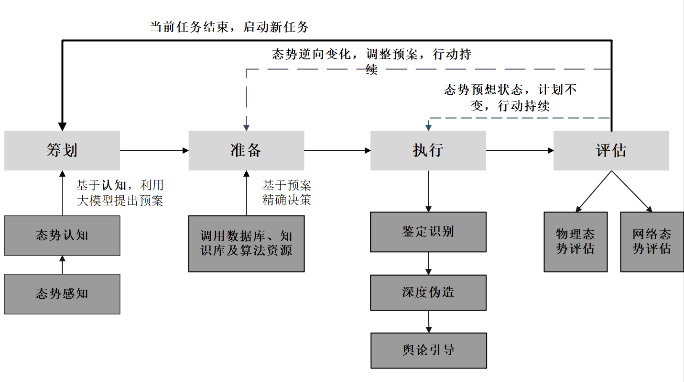
图 1 基于LLMs的认知战PREA环
Fig. 1 Cognitive Warfare PREA Ring based on the Big Model
2
引领性技术研究
2.1 态势感知技术研究
在军事领域,态势感知技术可高效处理不全面且模糊的信息,以应对具有高不确定性、复杂性、威胁性和紧迫性的对抗行动。
本文将LLMs在认知战应用划分为4层层次结构,包括态势感知层、态势理解层、态势分析层以及态势决策与应用层。在态势感知层面,LLMs将跨平台收集的多模态数据进行预处理,通过数据质量监控、多源数据处理等手段,获得高质量数据集。在态势理解层,模型通过数据分类、数据管理和因果推理获得对于态势的理解。在态势分析层,主要进行敌我力量变化预测、网络环境威胁预测和国际政策影响分析。在态势决策和应用层面,LLMs提供动态和多维度的决策支持,对潜在风险进行深入评估,并根据评估结果制作出清晰并具有较高可执行性的解决方案。具体应用框架如图2所示。

图 2 LLMs应用框架
Fig. 2 Large model application framework
2.1.1 态势感知层
1)异常事件检测与早期预警
2)数据质量监控与优化
利用LLMs进行数据处理可以有效提高数据质量。LLMs能够快速筛选、分类和整合原始情报数据,将其转换为结构化、清晰的信息,提高情报分析效率和准确性。
3)多模态知识融合
4)资源动态分配与调度
LLMs具有强大的数据分析和逻辑推理能力,可以灵活地根据不同的任务快速规划最佳解决路径,并进行资源的动态分配和调度,以适应不断变化的环境和任务需求。相比传统的强化学习方法,LLMs能够深入认知环境,综合考虑各种动态信息,制定最优的应对方案,提高资源利用效率和任务执行效率。
2.1.2 态势理解层
1)时序分析和关系网络建模
时序分析和关系网络建模也是认知战领域不可或缺的任务。LLMs的出现为这些任务带来新的可能性,具备自动特征提取能力,能够从大量时序数据中学习复杂模式和规律。通过训练这些模型,能够准确预测和分析时序数据,更好地理解认知战领域中的动态变化和趋势,揭示关键节点、社区结构和影响力传播机制,为决策者提供有价值的信息和洞见。
3)多任务决策与意图判断
在通用人工智能领域,多任务决策与意图判断已然成为新的重要研究方向。目前,LLMs在多任务决策与意图研判方面显示出巨大潜力。在认知战领域的实际应用中,面对众多复杂的多任务决策挑战,例如公众舆论风险评估和行为模式分析,LLMs能够并行处理多项任务,为复杂的决策制定提供有效支持。通过执行“因果推理”[21],模型能够辨识并阐释特定行为背后的驱动因素或目的,结合目标历史行为和环境制约因素,对未来潜在的发展趋势做出合理的预测。
2.1.3 态势分析层
1)认知战双方力量变化预测
2)网络环境威胁预测
LLMs的一个突出特点是它们能够融合多样化的非常规数据资源[22]。例如,这些模型可以吸收国际政治格局变化、科技发展步伐以及经济指标等方面的信息,以此来分析这些宏观因素可能对网络空间状况产生的何种影响。这种跨领域的分析能力让决策者能够全方位地把握认知领域竞争的多个层面,并在策划战略和战术时,将更多变量纳入考量。此外,通过整合强化学习算法,LLMs能够在模拟训练环境中不断地对未知或难以量化的情境进行“学习”与“适应”,进而得出符合当前网络环境态势的更为准确的预测[23]。
2.1.4 态势决策与应用层
1)风险和策略评估
在实际应用中,LLMs可将分析与预测的成果转化为实用的行动指导,利用其复杂的算法和人工智能技术,增强决策分析的深度和广度。此外,通过整合数学和统计分析工具,LLMs能够在考虑众多变量和条件的基础上,对决策的潜在风险与收益进行评估。
2)决策选项生成
大型模型利用自然语言生成技术将复杂数据转化为易理解的报告。结合实时数据流,它们提供动态决策支持,可实时更新选项。模型与本地知识库协同工作,分析决策者查询,提供最相关信息并生成选项内容。
3)动态决策支持报告生成
2.2 态势认知技术研究
态势认知旨在处理中长势信息,以达到超越表面事实的深度理解、判断和预测水平。态势认知涉及到对敌人、我方以及战场环境所处状态的实时感知,以及对战斗进程演变的洞察,是执行作战指挥和决策制定不可或缺的基石。国际上存在着多种态势感知和战略预警系统,这些系统通过实时追踪全球新闻媒体和社交媒体等关键信息源,全面搜集互联网上的数据。利用大数据分析技术对热点事件和敏感信息进行深入挖掘,进而实现对全球热点动态的实时监控和对潜在冲突的即时预警[24]。
WENG提出的基于LLMs的AI agent框架强调记忆的重要性,其中长期记忆主要用于存储LLMs中的编码知识,而短期记忆则承载了对外界环境和提示词的感知[25]。如图3所示,在认知战中,LLMs能够理解用自然语言描述的任务目标和环境状态,将其输入LLMs后,唤醒LLMs内部存储的知识,这些知识将通过LLMs输入到PREA环和观察-判断-决策-行动(observe-orient-decide-act,OODA)环中,以指导PREA环和OODA环在认知战中的行动。PREA环主要负责组织任务,它负责对任务目标进行深入的研究和分析,以了解敌方的认知状态和意图。通过对信息的收集和分析,PREA环能够制定出相应的行动计划,指导LLMs在认知战中采取相应的行动。同时,PREA环还能够根据环境反馈和LLMs的内部知识,对任务进行实时的调整和优化,以适应认知战的动态变化;而OODA环则主要执行行动角色,它通过对敌方行动和环境的观察,以及对敌方意图的定位,做出相应的决策。在认知战中,OODA环的目标是迅速而准确地执行决策,以取得战斗的优势。在认知战的过程中,LLMs依据环境反馈微调形成工作记忆的方法,不断适应环境,认知环境。同时,PREA环与OODA环角色也根据环境需要不断进行转换,以实现作战目标,满足灵活多变的战术需求,适应战场环境。
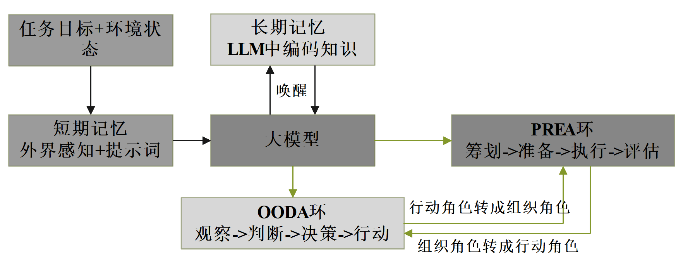
图 3 LLMs驱动的OODA-PREA
Fig. 3 Large model-driven OODA-PREA
不少学者已经利用LLMs进行领域信息任务鉴别。潘雪峰等利用ChatGPT鉴别健康谣言,鉴别准确率达到93.1%[26]; Chen等提出了一种基于循环神经网络(recurrent neural network,RNN) 的虚假新闻检测模型,捕捉相关新闻内容随时间的上下文变化,进而检测新闻的准确性[27]。沈瑞琳等运用迁移学习的思想分析和使用新闻的评论数据,将模型的特征提取网络进行微调,提取出来的新闻评论文本可以应用到后续的检测中[28]。
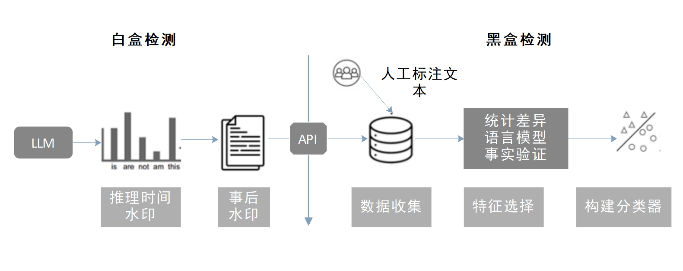
图 4 LLMs生成文本检测[29]
Fig. 4 LLMs Generated Text Detection[29]
2.4 信息作战技术研究
掌握信息作战工具精准生成的关键技术,能够有针对性地生成虚假情报信息,实现定向欺诈,破坏对方信息体系,影响敌方作战决策和行动,削弱敌方战斗力。
2.4.1 基于大型预训练模型的文本生成技术
文本生成技术可以广泛应用于虚假航空情报、虚假新闻文本等类型的信息作战工具生成,了解和掌握文本生成的技术范式、将文本生成技术化为己用,对强化认知域精准作战能力具有重要的现实意义。
LLMs主要通过在大量无标签数据上进行预训练的模型,然后在具体任务上进行微调。“预训练-微调”的范式使得LLMs能够从自然语言中捕捉到更多细微信息,为各种下游任务提供更丰富的语料信息,从而高效实现下游任务。
LLMs使用Transformer的Decoder结构,并对Transformer Decoder进行了一些改动,只保留 Mask Multi-Head Attention。使用LLMs生成文本的主要步骤如下。

2.4.2 基于大型预训练模型的视频生成技术
在信息时代,文生视频(text generated vedio, TGV)、音生视频(audio generated vedio, AGV)、图生视频(image generated vedio, IGV)等多媒体信息对网络空间认知战产生了深远影响。这些视频形式不仅有效传播信息,还对认知和心理造成显著影响。Sora是一款由Open AI开发的基于深度学习TGV模型,是视频生成领域的突出代表。它利用文本条件扩散模型、时空Transformer架构、大规模视频数据集训练等先进技术,使得TGV成为可能,同时也使得生成的视频在时空一致性、视频高分辨率、逼真视觉效果等方面遥遥领先。
利用Sora可以生成以假乱真的高质量视频,TGV在网络空间认知战领域也展现出巨大应用潜力。Sora的应用包括但不限于虚假信息制作与传播、心理操纵、情报收集与欺骗、宣传和舆论战等。比如通过Sora制作虚假会议讲话或领导者发言的视频,在很大程度上能够对国内甚至全球民众产生误导作用,动摇民心,同时也会影响到国际社会的态度和立场,以达到缓解战场形式,甚至扭转战场局面的作用。
LLMs视频生成技术在认知战领域具有广泛的应用潜力,可以用于制作虚假信息、进行心理操纵、情报欺骗、宣传和舆论战,以及心理防护和心理训练等,进而改变战场的态势和心理环境。
3
LLMs发展的挑战与机遇
LLMs的迅速发展无疑给网络空间认知战提供了高效的“武器”,在该领域展现出了广泛的应用潜力,但在实际部署和实施过程中,LLMs在网络空间认知战中的应用仍面临多项关键挑战。
3.1 大模型幻觉
在自然语言处理或者大模型的语境下,幻觉是一种虚假的感知,尽管在感知上显得真实。换句话说,大模型生成的流畅自然的文本在现实生活中可能是不真实或无意义的,与心理幻觉难以与其他 “真实”感知区分开来类似,幻觉文本也难以一眼捕捉。Li等人的研究讲大模型幻觉分为内在幻觉与外在幻觉,内在幻觉指与源内容相矛盾的生成输出,外部幻觉指既无法从源内容中得到支持,也无法从源内容中得到反驳的输出[33]。
3.2 大模型推理时效性
在网络空间认知战领域,每秒钟都会生成上亿条不同内容、不同类型的多源异构、高维特征的海量数据,因此生成内容的实时性和及时性是取得先机的关键要求。目前,导致LLMs推理限制资源有效利用的主要问题在于推理在Prompt阶段和Token生成阶段的特征差异。在Prompt阶段,LLMs 并行处理所有用户Prompt,有效地利用 GPU 计算。但是,在Token生成阶段,LLM 会按顺序生成每个输出Token,并受到 GPU 内存带宽的限制。即使采用最先进的批处理机制,这两个阶段之间的差异也会导致整体硬件利用率低。
微软研究人员通过创建 Splitwise来将Prompt阶段和token生成阶段分离到单独的计算机上来优化利用可用硬件[34]。此外,利用KV Cache[35]、Iteration-level scheduling[36]、PagedAttention[37]等方法进行框架优化,也能提高LLMs运行效率,使其实现快速响应。
3.3 大模型可解释性
大模型仍处于“黑箱”状态,其内部机制不能明确地展示出来。此外,LLMs在训练过程中依赖大规模文本语料,这些训练数据中的偏见和错误等都可能影响模型,但很难完整判断训练数据的质量对模型的影响程度,而这种缺乏透明度的情况也使得LLMs在网络空间认知战的应用中存在着风险。决策者对生成内容及其产生的效果极易产生怀疑,并且目前仍缺乏对模型可解释性的自动评估指标和方法,因此,无法在短时间内验证生成文本的有效性。
3.4 大模型安全与隐私问题
将LLMs应用在网络空间认知战上时,不可避免地要使用大量的语料进行训练,为使大模型能实现更高的精确度,就必然要提供给其更精细的信息。而一旦使用过程中由于自身模型失误或其他方面攻击而出现语料泄露,可能会引发严重的安全风险,甚至存在扭转网络空间战局势的可能。目前,大模型的应用漏洞可以分为AI 模型固有漏洞和非AI模型固有漏洞[39],如何进行防御是LLMs在网络空间认知战应用中亟需解决的关键问题。
部分学者提出将可信执行环境(trusted execution environment,TEE)等隐私计算技术与大模型结合,用多项式替代非线性激活函数,从而将同态加密、秘密共享等方法应用于大模型[40-41],同时,通过在云端部署可信执行环境,并只在可信执行环境内部进行解密输入数据和推理操作,也可以避免第三方的窃取[42-43]。但上述方法方法也存在着硬件支持和可信执行环境内部的容量问题,不支持广泛应用[44]。此外,LLM 模型本身含有基于人类反馈的强化学习(RLHF)模块,通过将人类纳入训练循环,对提问和输出内容进行审核。因此培训专业人才也至关重要[45]。目前大语言模型应用前景十分广泛,但其安全与隐私问题也亟需提出更有效的方法进行解决。
4
结论与展望
References
[1] 蒋琪, 申超, 张冬青 . 认知/动态与分布式作战对导弹武器装备发展影响研究 [J]. 战术导弹技术, 2016,(3) : 1-6.
JIANG Q,SHEN C,ZHANG D Q. Research on the impact of cognitive/dynamic and distributed operations on missile weaponry development[J]. Tactical Missile Technology, 2016,(3) : 1-6.(in Chinese)
[2] 张弛, 翁方宸, 张玉清 . ChatGPT在网络安全领域的应用、现状与趋势 [J]. 信息安全研究, 2023, 9 (6) : 500-509.