原神Agent,字节出品
鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
糟糕!现在Agent也会这招了:原神,启动!

咳咳,这其实是字节最新手搓出来的原神Agent——Lumine。
不仅在《原神》里玩得很6,跑图开荒以及动辄几个小时的长主线任务,Lumine都能自己搞定,而且水平还不菜。
(唔,我的膝盖中箭了)
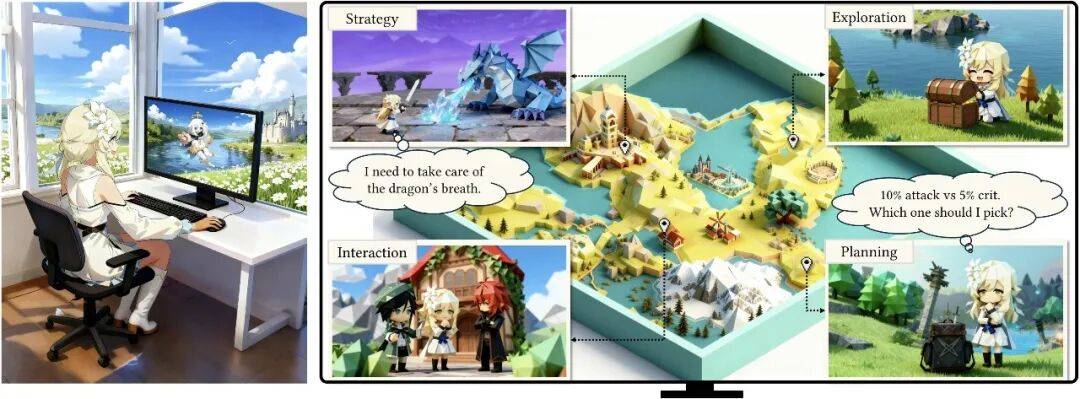
而且还能举一反三玩其它没学过的游戏,例如《鸣潮》、《崩铁》,还有难倒一众手残党的《黑悟空》……也是so easy~

话不多说,先上效果:
原神实机效果演示
跑图碰到小怪?Lumine:交给我吧!
不仅能够动态追踪敌人位置、精准射击远距离目标,队伍角色切换也相当流畅,当然珍贵的宝箱也要收入囊中~
难度next level,Boss战中,Lumine也展现出了超强的理解能力。
各种解谜关卡也是不在话下,比如沿着风场方向收集风神瞳:
这空间感知能力nice!
还能在多个NPC环境中锁定指定对象,完成NPC对话。
一些GUI操作,比如材料制作、使用传送锚点、切换角色武器,Lumine都能通过鼠标移动的方式完成。
而对于一些更为复杂的长指令,只需要为Lumine提供清楚任务的先验信息或者任务步骤,Be like:切换角色为凯亚,不断释放E技能冻结水面,以收集前方浮在水面上的风神瞳。
All in all,人类旅行者会的,这个Agent也可以会,这下新地图开荒再也不用担心没有游戏搭子啦~
那么到底是如何做到让Agent自己玩游戏的呢?
专为3D开发世界交互设计
首先Lumine是基于Qwen2-VL-7B-Base模型搭建的,继承了其在大规模网页数据训练中获得的多模态理解与生成能力。
然后采用类人交互范式,通过统一的语言空间建模所有操作和推理,实现感知、推理、行动的无缝融合。
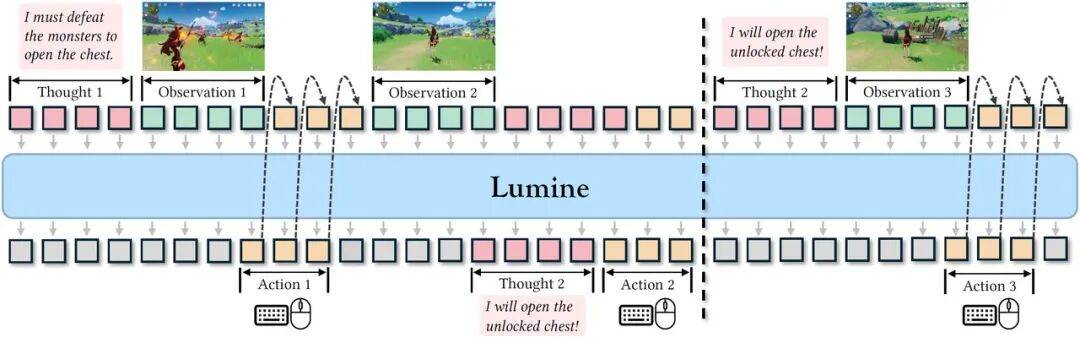
具体来说,包括三大核心机制设计:
1、感知空间(Observation Space):
在视觉输入上,将游戏画面帧调整至720P,然后以每200ms速度处理一帧,这样既能平衡文本可读性和计算效率,又能避免遗漏关键时序事件。
此外,保留历史推理轨迹与动作记录,为决策提供完整的上下文信息支撑。
2、 混合思考策略(HybridThinking):
要求Agent在每一步发生前,都要事先判断是否需要进行思考,仅在关键场景生成内心独白式推理(如环境突变、计划失效、新目标出现)。
简单场景(如常规移动、重复操作)则直接输出动作,提高计算效率。
3、键盘与鼠标操作建模(Keyboard and Mouse Modelling):
将所有操作都纳入语言空间,定义为鼠标位移和按键序列的格式。
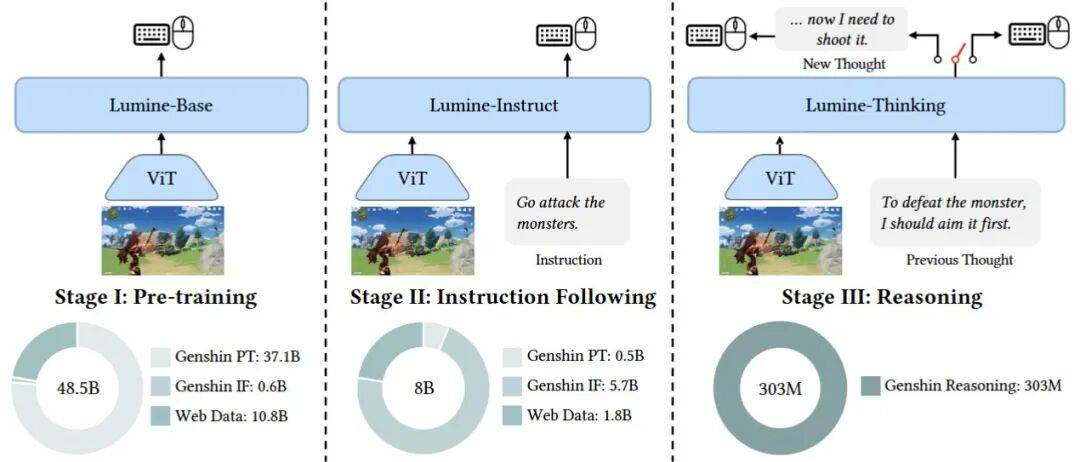
然后采集高质量《原神》操作数据,并执行三阶段训练流程:
第一阶段:预训练掌握基础动作。
混合80%游戏动作数据和20%多模态网页数据,让模型从图像-动作对中学习基础的视觉运动能力,同时保留模型通用知识与感知能力。
得到的Lumine-Base模型,逐步涌现出物体交互、基础战斗、GUI操作等核心能力,为后续理解游戏机制奠定了基础。
第二阶段:指令跟随训练。
使用38类任务场景下的200小时指令-图像-动作数据,让模型理解自然语言指令,并将动作与语言完成关联。
此时输出的Lumine-Instruct模型,可完成10秒至数分钟短周期任务,成功率超80%。
第三阶段:决策推理训练。
为了让模型学会自主规划、反思与修正,完成数小时以上的长任务,团队使用15小时的人工标注推理数据,并将指令输入替换为历史推理,让模型生成新推理和对应动作。
然后Lumine-Thinking就能在没有人类干预的情况下,自主完成长周期任务。
另外,为了解决模型在游戏中的实时交互问题,团队还进行了上下文管理和多维度实时优化。
通过滑动窗口机制与推理触发刷新策略,平衡 “历史信息利用” 与 “计算效率”,保障长周期任务中的行为一致性。
然后利用分阶段优化策略:流式LLM→张量并行→LLM量化→推测解码→基础设施优化,实现端到端延迟降至129.8ms。
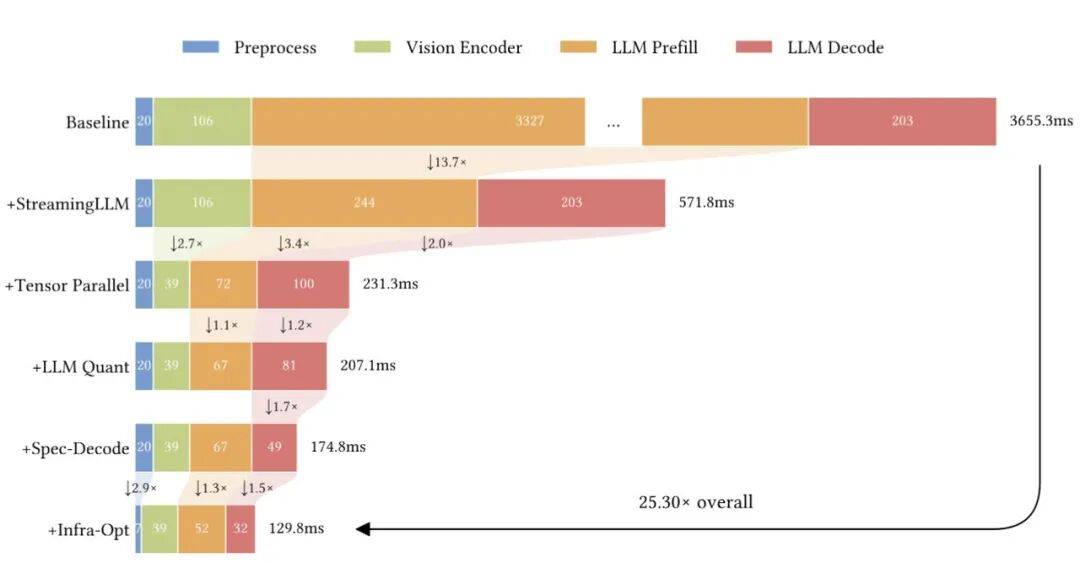
而这些也在实验结果中得以验证。
除了《原神》,其它游戏也都会
为了验证Lumine各版本(Base/Instruct/Thinking)在3D开放世界中的能力边界,实验分别对其在基础任务完成度、长周期剧情执行效率、跨场景泛化性以及跨游戏适配性上,与主流VLMs进行了对比。
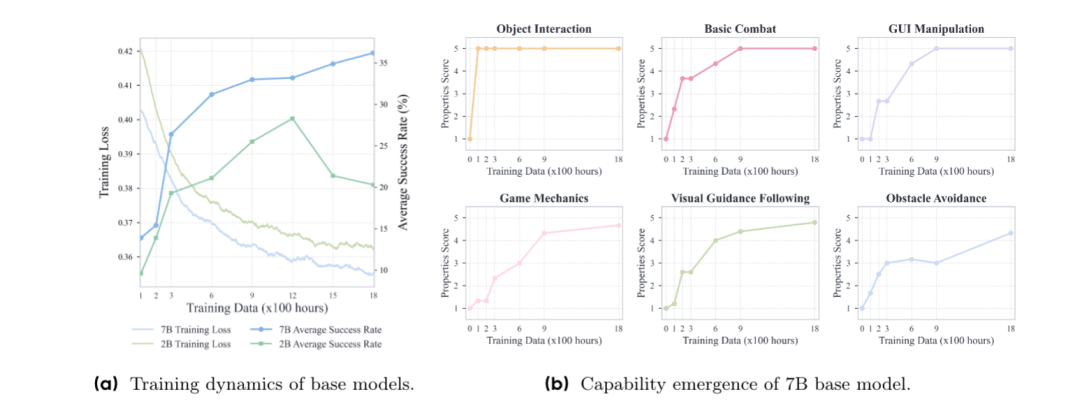
首先在无语言指令的情况下,Lumine-Base呈现阶梯式能力涌现:
基础交互能力:成功掌握物体交互(如拾取物品、打开宝箱)、2D GUI操作(如点击对话框、切换菜单)、基础移动(跑、跳、爬),总成功率超90%,但该阶段没有目标导向(如不会主动寻找任务物品)。
游戏机制理解:能够自发运用元素反应(如丽莎放电触发超导),理解游戏中存在体力值限制(在爬高时会自动停顿恢复体力),但复杂机制(如元素爆发充能、角色切换策略)仍需后续训练强化。
场景适配局限:仅能在训练覆盖的蒙德区域活动,一旦进入未训练场景(如璃月)后,因地形识别不足,容易卡在障碍物处,没有自主导航能力。
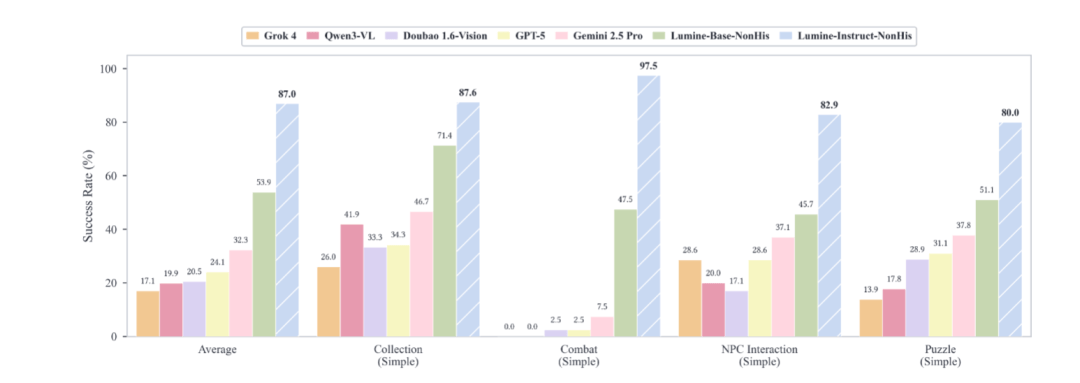
然后针对语言指令驱动的短周期任务,Lumine-Instruct在全类别任务完成率中均领先于主流VLMs。
例如简单任务上,Lumine-Instruct的成功率为92.5%,与GPT-5(89.8%)差距较小,但动作连贯性更好。
在困难任务中,这种优势则更为显著,成功率为76.8%,远超第二名Gemini 2.5 Pro的52.4%,表现出更好的战术规划。
在未见过的璃月场景中,它也是唯一能够在陌生区域中自主导航的模型。
然后测试Lumine-Thinking在无人工干预下的长剧情执行效果,以蒙德主线为核心场景。
第一章总耗时56分钟,任务完成率100%,全程无卡顿。相比之下,GPT-5耗时112分钟,Gemini 2.5 Pro未完成。
第二、三章合计耗时4.7小时,完成率为98.2%,其它模型中只有Gemini 2.5 Pro完成65%任务,耗时超8小时。
而在未训练过的其它三款游戏中,Lumine-Thinking也表现出了其通用Agent特性。

比如和《原神》同为开放世界的《鸣潮》,在主线前100分钟剧情里,Lumine-Thinking总耗时102分钟,完成率100%,证明了其对相似玩法的快速适配能力。
玩法差异较大的回合制开放世界《崩坏·星穹铁道》中,Lumine-Thinking通过第一章主线总耗时7.2小时,完成率92.3%,是唯一能完整通关的模型。
高难度的3A游戏《黑神话·悟空》中,要完成新手教程和第一章前半段,Lumine-Thinking需耗时2.1小时,完成率85.7%。在躲避Boss攻击上整体行动流畅,但是在写实画风识别上,存在误判的情况出现,还需强化视觉动态特征识别。
总的来说,相比于依赖预定义动作库的VLMs,Lumine的动作响应速度更快,从感知到行动的过程更高效;仅在关键节点启动推理的策略,也更好地保证了长任务连贯性;同时拥有更强的跨场景跨游戏的泛化能力。
OMT
其实游戏场景,一直都是通用Agent的试验场。

除了字节,谷歌等公司也都在使用游戏场景训练Agent,比如他们最新推出的SIMA 2——一个能够在《模拟山羊3》等虚拟游戏场景中遵循基本指令的通用型AI。
相比于上一代Agent SIMA,它这次基于Gemini模型建立,不仅能够遵循基本指令,而且集成了强大的推理能力,可以理解和完成长时间的复杂任务、文本语言或图像等多模态提示,还能理解不同的语言甚至标点符号。
在Genie 3全新生成的世界中,SIMA 2也能合理地自我定位,理解用户指令、采取合理行动。

而无论是字节,还是谷歌DeepMind,他们都代表了一条非常清晰的Agent发展路径:在大型3D游戏中构建具身AGI。
他们相信,游戏里的通用Agent终有一天,会进入现实物理世界,转变为最终的具身智能。
参考链接:
[1]https://www.lumine-ai.org/
[2]https://arxiv.org/abs/2511.08892
[3]https://deepmind.google/blog/sima-2-an-agent-that-plays-reasons-and-learns-with-you-in-virtual-3d-worlds/